Despite possessing impressive skills, Large Language Models (LLMs) often fail unpredictably, demonstrating inconsistent success in even basic common sense reasoning tasks. This unpredictability poses a significant challenge to ensuring their safe deployment, as identifying and operating within a reliable "safe zone" is essential for mitigating risks. To address this, we present PredictaBoard, a novel collaborative benchmarking framework designed to evaluate the ability of score predictors (referred to as assessors) to anticipate LLM errors on specific task instances (i.e., prompts) from existing datasets. PredictaBoard evaluates pairs of LLMs and assessors by considering the rejection rate at different tolerance errors. As such, PredictaBoard stimulates research into developing better assessors and making LLMs more predictable, not only with a higher average performance. We conduct illustrative experiments using baseline assessors and state-of-the-art LLMs. PredictaBoard highlights the critical need to evaluate predictability alongside performance, paving the way for safer AI systems where errors are not only minimised but also anticipated and effectively mitigated.

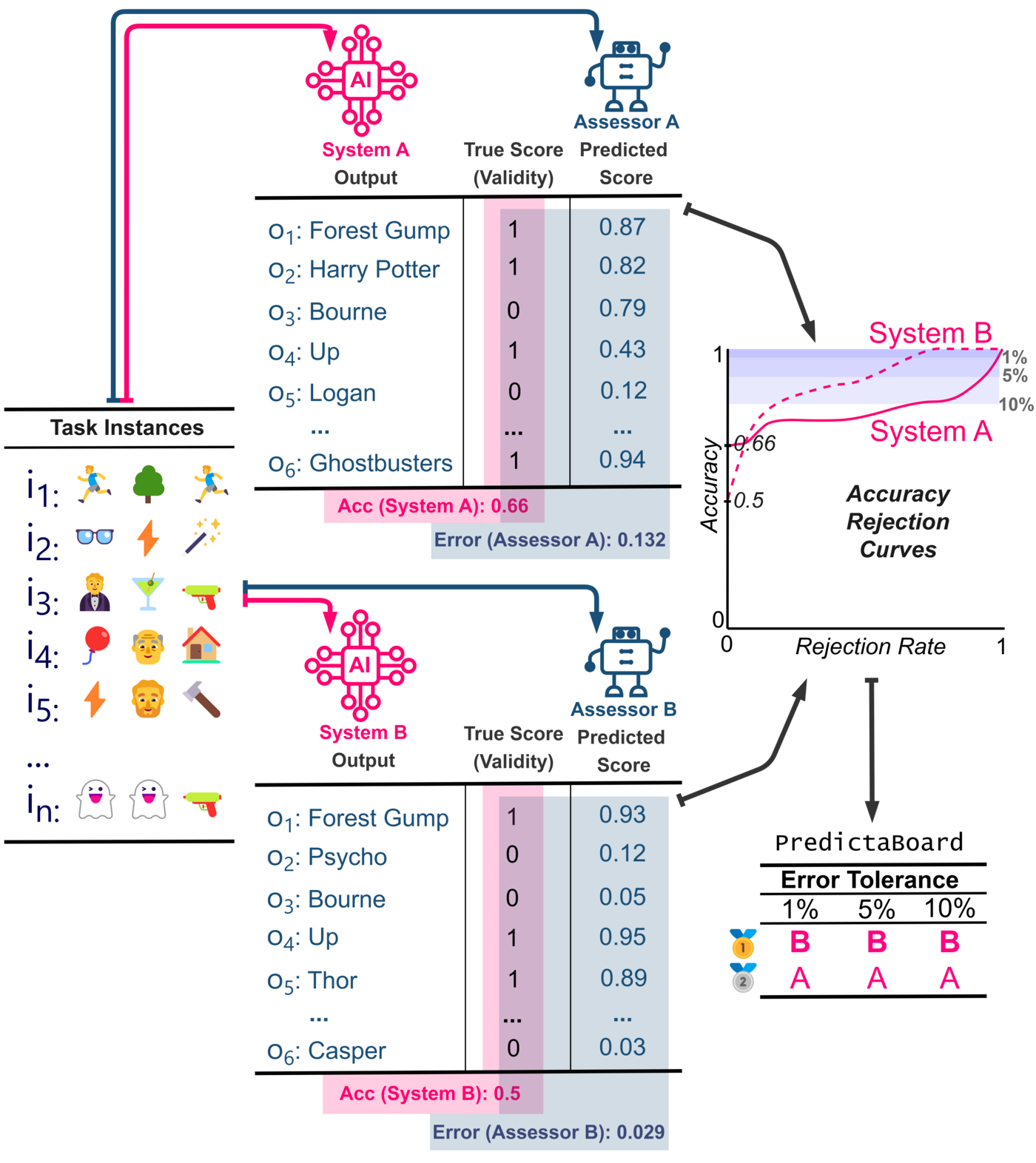
In the plot above, each system corresponds to a LLM-assessor pair. Systems A and B have overall accuracy a and b respectively, with b larger than a. However, for an error tolerance of 20%, System A has a larger non-rejection rate. We say therefore that System A's 0.8 PVR is larger than System B's (where 0.8 refers to the minimum required accuracy).
Predictaboard uses a split of MMLU-Pro to train assessors and another one to test them; instead, BBH is kept as Out-Of-Distribution dataset. The in-distribution and out-of-distribution leaderboards below show the Predictably Valid Region (PVR) of the considered LLM-assessor pairs for three minimum accuracy thresholds (0.8, 0.9, 0.95) and the Area Under the ARC (AUARC).
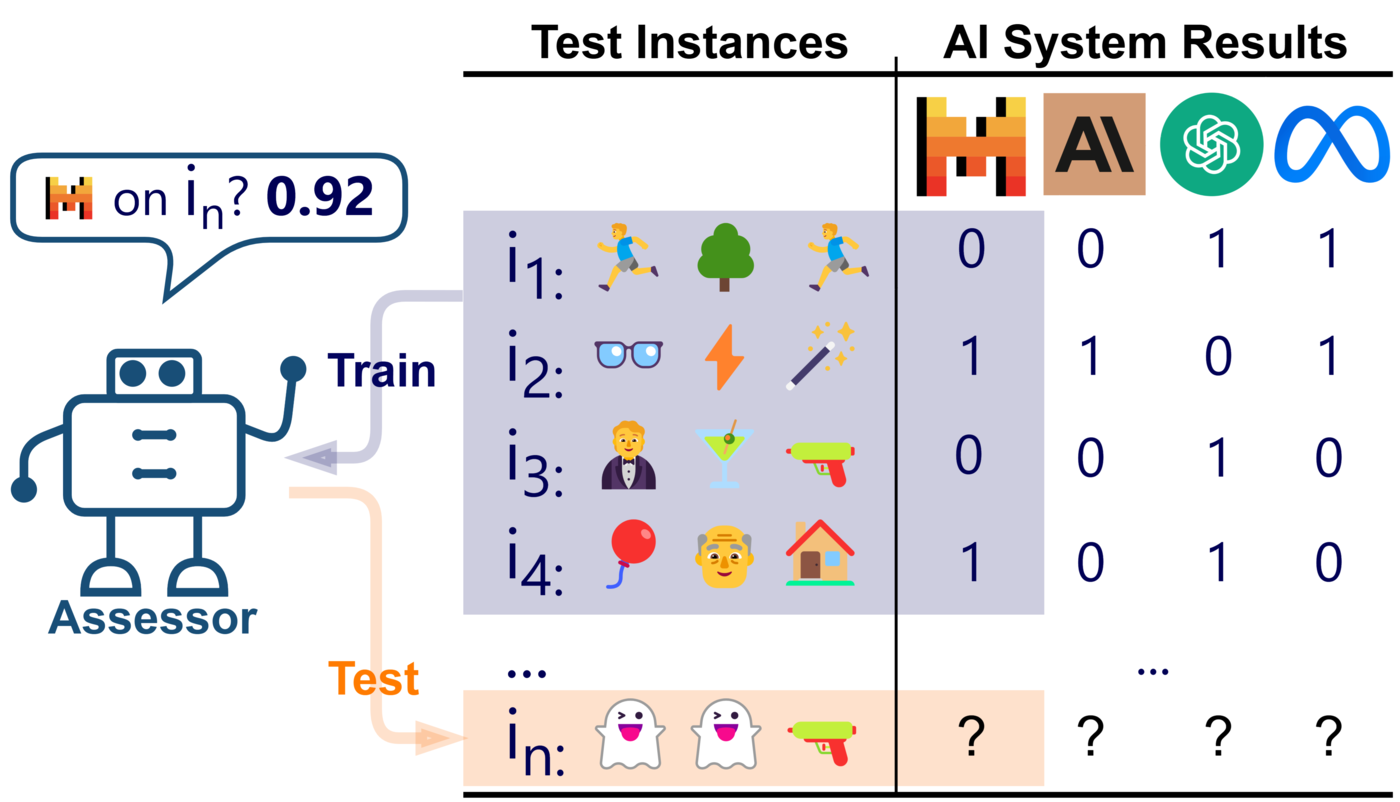
Our initial results use a set of baseline assessors based on various text embeddings approaches and
41 LLMs.
Our project repo makes it easy to contribute new LLMs or assessors, test them on this fixed setup, and add them to the leaderboards. Please refer to instructions in the repo.
The table below shows the results of the considered LLM-assessor pairs for three minimum accuracy thresholds (0.8, 0.9, 0.95). At a threshold of 0.8, the top LLM-assessor pairs perform well, as assessors can reliably predict success. However, when the threshold increases to 0.9 or higher, the predictably valid region drops significantly, as assessors face greater difficulty in anticipating failures. The best-performing pairs consistently include LLMs with high average accuracy, which aligns with expectations.
| LLM | Predictive Method | Features | 0.8 PVR | 0.9 PVR | 0.95 PVR | Area under ARC |
|---|---|---|---|---|---|---|
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.39 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.377 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | Logistic Regression (l1) | OpenAI | 0.172 | 0.081 | 0 | 0.726 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.248 |
| wave-on-discord/qwent-7b | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.185 |
| Aryanne/SuperHeart | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.431 |
| Intel/neural-chat-7b-v3-2 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.277 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.336 |
| Intel/neural-chat-7b-v3-1 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.298 |
| ssmits/Qwen2.5-95B-Instruct | Logistic Regression (l1) | OpenAI | 0.162 | 0.061 | 0 | 0.679 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.21 |
| migtissera/Tess-v2.5.2-Qwen2-72B | Logistic Regression (l1) | OpenAI | 0.212 | 0.04 | 0.01 | 0.715 |
| migtissera/Llama-3-70B-Synthia-v3.5 | Logistic Regression (l1) | OpenAI | 0.131 | 0.03 | 0.02 | 0.654 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.34 |
| Stark2008/VisFlamCat | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.337 |
| migtissera/Trinity-2-Codestral-22B | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.337 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.32 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.25 |
| apple/DCLM-7B | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.307 |
| Intel/neural-chat-7b-v3-3 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.284 |
| migtissera/Tess-3-Mistral-Nemo-12B | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.306 |
| migtissera/Llama-3-8B-Synthia-v3.5 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.308 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.417 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.303 |
| NousResearch/Hermes-3-Llama-3.1-70B | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.507 |
| OpenAI/GPT-4o-2024-08-06 | Logistic Regression (l1) | OpenAI | 0.788 | 0.162 | 0.051 | 0.847 |
| BlackBeenie/llama-3-luminous-merged | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.398 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.119 |
| migtissera/Tess-3-7B-SFT | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.307 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.318 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | Logistic Regression (l1) | OpenAI | 0.232 | 0.051 | 0.02 | 0.72 |
| OpenAI/GPT-4o-mini | Logistic Regression (l1) | OpenAI | 0.354 | 0 | 0 | 0.772 |
| upstage/solar-pro-preview-instruct | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.568 |
| Stark2008/LayleleFlamPi | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.336 |
| NousResearch/Yarn-Llama-2-13b-128k | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.257 |
| OpenAI/GPT-4o-2024-05-13 | Logistic Regression (l1) | OpenAI | 0.808 | 0.162 | 0 | 0.844 |
| AbacusResearch/Jallabi-34B | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.505 |
| Stark2008/GutenLaserPi | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.341 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.323 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.119 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.366 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.401 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.39 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.384 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.389 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | Logistic Regression (l1) | Word2Vec | 0.121 | 0 | 0 | 0.707 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | Logistic Regression (l1) | FastText | 0.02 | 0 | 0 | 0.692 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.244 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.239 |
| wave-on-discord/qwent-7b | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.163 |
| wave-on-discord/qwent-7b | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.167 |
| Aryanne/SuperHeart | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.406 |
| Aryanne/SuperHeart | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.406 |
| Intel/neural-chat-7b-v3-2 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.283 |
| Intel/neural-chat-7b-v3-2 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.285 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.347 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.341 |
| Intel/neural-chat-7b-v3-1 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.276 |
| Intel/neural-chat-7b-v3-1 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.269 |
| ssmits/Qwen2.5-95B-Instruct | Logistic Regression (l1) | Word2Vec | 0.03 | 0 | 0 | 0.652 |
| ssmits/Qwen2.5-95B-Instruct | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.638 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.201 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.206 |
| migtissera/Tess-v2.5.2-Qwen2-72B | Logistic Regression (l1) | Word2Vec | 0.091 | 0 | 0 | 0.689 |
| migtissera/Tess-v2.5.2-Qwen2-72B | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.675 |
| migtissera/Llama-3-70B-Synthia-v3.5 | Logistic Regression (l1) | Word2Vec | 0.03 | 0 | 0 | 0.626 |
| migtissera/Llama-3-70B-Synthia-v3.5 | Logistic Regression (l1) | FastText | 0.01 | 0 | 0 | 0.618 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.337 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.346 |
| Stark2008/VisFlamCat | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.345 |
| Stark2008/VisFlamCat | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.335 |
| migtissera/Trinity-2-Codestral-22B | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.335 |
| migtissera/Trinity-2-Codestral-22B | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.336 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.321 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.326 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.248 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.263 |
| apple/DCLM-7B | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.318 |
| apple/DCLM-7B | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.317 |
| Intel/neural-chat-7b-v3-3 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.277 |
| Intel/neural-chat-7b-v3-3 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.278 |
| migtissera/Tess-3-Mistral-Nemo-12B | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.279 |
| migtissera/Tess-3-Mistral-Nemo-12B | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.291 |
| migtissera/Llama-3-8B-Synthia-v3.5 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.316 |
| migtissera/Llama-3-8B-Synthia-v3.5 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.295 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.412 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.395 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.308 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.316 |
| NousResearch/Hermes-3-Llama-3.1-70B | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.5 |
| NousResearch/Hermes-3-Llama-3.1-70B | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.498 |
| OpenAI/GPT-4o-2024-08-06 | Logistic Regression (l1) | Word2Vec | 0.657 | 0 | 0 | 0.805 |
| OpenAI/GPT-4o-2024-08-06 | Logistic Regression (l1) | FastText | 0.515 | 0 | 0 | 0.803 |
| BlackBeenie/llama-3-luminous-merged | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.387 |
| BlackBeenie/llama-3-luminous-merged | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.391 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.121 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.12 |
| migtissera/Tess-3-7B-SFT | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.295 |
| migtissera/Tess-3-7B-SFT | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.308 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.311 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.327 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | Logistic Regression (l1) | Word2Vec | 0.131 | 0.03 | 0 | 0.703 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | Logistic Regression (l1) | FastText | 0.061 | 0 | 0 | 0.695 |
| OpenAI/GPT-4o-mini | Logistic Regression (l1) | Word2Vec | 0.111 | 0.01 | 0.01 | 0.737 |
| OpenAI/GPT-4o-mini | Logistic Regression (l1) | FastText | 0.051 | 0 | 0 | 0.721 |
| upstage/solar-pro-preview-instruct | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.55 |
| upstage/solar-pro-preview-instruct | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.524 |
| Stark2008/LayleleFlamPi | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.321 |
| Stark2008/LayleleFlamPi | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.334 |
| NousResearch/Yarn-Llama-2-13b-128k | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.271 |
| NousResearch/Yarn-Llama-2-13b-128k | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.26 |
| OpenAI/GPT-4o-2024-05-13 | Logistic Regression (l1) | Word2Vec | 0.717 | 0.03 | 0 | 0.811 |
| OpenAI/GPT-4o-2024-05-13 | Logistic Regression (l1) | FastText | 0.586 | 0.01 | 0 | 0.805 |
| AbacusResearch/Jallabi-34B | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.52 |
| AbacusResearch/Jallabi-34B | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.52 |
| Stark2008/GutenLaserPi | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.34 |
| Stark2008/GutenLaserPi | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.342 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.33 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.326 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.116 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.112 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.364 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.361 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.394 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.397 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | Logistic Regression (l1) | Ngrams-1 | 0.071 | 0.01 | 0 | 0.694 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.257 |
| wave-on-discord/qwent-7b | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.161 |
| Aryanne/SuperHeart | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.4 |
| Intel/neural-chat-7b-v3-2 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.276 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.338 |
| Intel/neural-chat-7b-v3-1 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.285 |
| ssmits/Qwen2.5-95B-Instruct | Logistic Regression (l1) | Ngrams-1 | 0.051 | 0 | 0 | 0.644 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.199 |
| migtissera/Tess-v2.5.2-Qwen2-72B | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.686 |
| migtissera/Llama-3-70B-Synthia-v3.5 | Logistic Regression (l1) | Ngrams-1 | 0.03 | 0.01 | 0 | 0.627 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.341 |
| Stark2008/VisFlamCat | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.337 |
| migtissera/Trinity-2-Codestral-22B | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.331 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.32 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.241 |
| apple/DCLM-7B | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.306 |
| Intel/neural-chat-7b-v3-3 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.271 |
| migtissera/Tess-3-Mistral-Nemo-12B | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.281 |
| migtissera/Llama-3-8B-Synthia-v3.5 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.31 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.4 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.319 |
| NousResearch/Hermes-3-Llama-3.1-70B | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.5 |
| OpenAI/GPT-4o-2024-08-06 | Logistic Regression (l1) | Ngrams-1 | 0.677 | 0.071 | 0 | 0.829 |
| BlackBeenie/llama-3-luminous-merged | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.391 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.119 |
| migtissera/Tess-3-7B-SFT | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.298 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.311 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | Logistic Regression (l1) | Ngrams-1 | 0.02 | 0 | 0 | 0.689 |
| OpenAI/GPT-4o-mini | Logistic Regression (l1) | Ngrams-1 | 0.162 | 0 | 0 | 0.74 |
| upstage/solar-pro-preview-instruct | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.558 |
| Stark2008/LayleleFlamPi | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.321 |
| NousResearch/Yarn-Llama-2-13b-128k | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.249 |
| OpenAI/GPT-4o-2024-05-13 | Logistic Regression (l1) | Ngrams-1 | 0.717 | 0.02 | 0 | 0.817 |
| AbacusResearch/Jallabi-34B | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.504 |
| Stark2008/GutenLaserPi | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.335 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.319 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.117 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.371 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.395 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.39 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | Logistic Regression (l2) | OpenAI | 0.192 | 0.071 | 0 | 0.731 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.245 |
| wave-on-discord/qwent-7b | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.169 |
| Aryanne/SuperHeart | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.427 |
| Intel/neural-chat-7b-v3-2 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.285 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.332 |
| Intel/neural-chat-7b-v3-1 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.294 |
| ssmits/Qwen2.5-95B-Instruct | Logistic Regression (l2) | OpenAI | 0.172 | 0.02 | 0 | 0.683 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.206 |
| migtissera/Tess-v2.5.2-Qwen2-72B | Logistic Regression (l2) | OpenAI | 0.242 | 0.061 | 0.03 | 0.719 |
| migtissera/Llama-3-70B-Synthia-v3.5 | Logistic Regression (l2) | OpenAI | 0.152 | 0.051 | 0 | 0.66 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.34 |
| Stark2008/VisFlamCat | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.339 |
| migtissera/Trinity-2-Codestral-22B | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.34 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.328 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.242 |
| apple/DCLM-7B | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.311 |
| Intel/neural-chat-7b-v3-3 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.291 |
| migtissera/Tess-3-Mistral-Nemo-12B | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.301 |
| migtissera/Llama-3-8B-Synthia-v3.5 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.302 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.395 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.319 |
| NousResearch/Hermes-3-Llama-3.1-70B | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.495 |
| OpenAI/GPT-4o-2024-08-06 | Logistic Regression (l2) | OpenAI | 0.808 | 0.222 | 0 | 0.85 |
| BlackBeenie/llama-3-luminous-merged | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.391 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.118 |
| migtissera/Tess-3-7B-SFT | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.318 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.311 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | Logistic Regression (l2) | OpenAI | 0.242 | 0.071 | 0.01 | 0.723 |
| OpenAI/GPT-4o-mini | Logistic Regression (l2) | OpenAI | 0.444 | 0 | 0 | 0.782 |
| upstage/solar-pro-preview-instruct | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.565 |
| Stark2008/LayleleFlamPi | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.332 |
| NousResearch/Yarn-Llama-2-13b-128k | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.254 |
| OpenAI/GPT-4o-2024-05-13 | Logistic Regression (l2) | OpenAI | 0.848 | 0.192 | 0 | 0.85 |
| AbacusResearch/Jallabi-34B | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.506 |
| Stark2008/GutenLaserPi | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.338 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.322 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.118 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.373 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.395 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.398 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.378 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.395 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | Logistic Regression (l2) | Word2Vec | 0.101 | 0 | 0 | 0.706 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | Logistic Regression (l2) | FastText | 0.02 | 0.01 | 0.01 | 0.695 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.241 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.251 |
| wave-on-discord/qwent-7b | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.163 |
| wave-on-discord/qwent-7b | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.175 |
| Aryanne/SuperHeart | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.405 |
| Aryanne/SuperHeart | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.4 |
| Intel/neural-chat-7b-v3-2 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.274 |
| Intel/neural-chat-7b-v3-2 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.287 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.344 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.338 |
| Intel/neural-chat-7b-v3-1 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.276 |
| Intel/neural-chat-7b-v3-1 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.276 |
| ssmits/Qwen2.5-95B-Instruct | Logistic Regression (l2) | Word2Vec | 0.03 | 0 | 0 | 0.654 |
| ssmits/Qwen2.5-95B-Instruct | Logistic Regression (l2) | FastText | 0.03 | 0 | 0 | 0.644 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.202 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.208 |
| migtissera/Tess-v2.5.2-Qwen2-72B | Logistic Regression (l2) | Word2Vec | 0.101 | 0.01 | 0.01 | 0.691 |
| migtissera/Tess-v2.5.2-Qwen2-72B | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.679 |
| migtissera/Llama-3-70B-Synthia-v3.5 | Logistic Regression (l2) | Word2Vec | 0.04 | 0 | 0 | 0.627 |
| migtissera/Llama-3-70B-Synthia-v3.5 | Logistic Regression (l2) | FastText | 0.02 | 0 | 0 | 0.621 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.34 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.333 |
| Stark2008/VisFlamCat | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.338 |
| Stark2008/VisFlamCat | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.339 |
| migtissera/Trinity-2-Codestral-22B | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.339 |
| migtissera/Trinity-2-Codestral-22B | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.331 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.321 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.319 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.25 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.256 |
| apple/DCLM-7B | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.316 |
| apple/DCLM-7B | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.316 |
| Intel/neural-chat-7b-v3-3 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.265 |
| Intel/neural-chat-7b-v3-3 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.275 |
| migtissera/Tess-3-Mistral-Nemo-12B | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.284 |
| migtissera/Tess-3-Mistral-Nemo-12B | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.297 |
| migtissera/Llama-3-8B-Synthia-v3.5 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.31 |
| migtissera/Llama-3-8B-Synthia-v3.5 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.292 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.42 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.409 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.31 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.31 |
| NousResearch/Hermes-3-Llama-3.1-70B | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.497 |
| NousResearch/Hermes-3-Llama-3.1-70B | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.499 |
| OpenAI/GPT-4o-2024-08-06 | Logistic Regression (l2) | Word2Vec | 0.667 | 0 | 0 | 0.804 |
| OpenAI/GPT-4o-2024-08-06 | Logistic Regression (l2) | FastText | 0.636 | 0 | 0 | 0.806 |
| BlackBeenie/llama-3-luminous-merged | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.385 |
| BlackBeenie/llama-3-luminous-merged | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.388 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.124 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.129 |
| migtissera/Tess-3-7B-SFT | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.299 |
| migtissera/Tess-3-7B-SFT | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.297 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.312 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.317 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | Logistic Regression (l2) | Word2Vec | 0.131 | 0 | 0 | 0.701 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | Logistic Regression (l2) | FastText | 0.03 | 0.01 | 0.01 | 0.699 |
| OpenAI/GPT-4o-mini | Logistic Regression (l2) | Word2Vec | 0.101 | 0.01 | 0 | 0.735 |
| OpenAI/GPT-4o-mini | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.72 |
| upstage/solar-pro-preview-instruct | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.548 |
| upstage/solar-pro-preview-instruct | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.535 |
| Stark2008/LayleleFlamPi | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.321 |
| Stark2008/LayleleFlamPi | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.33 |
| NousResearch/Yarn-Llama-2-13b-128k | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.262 |
| NousResearch/Yarn-Llama-2-13b-128k | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.263 |
| OpenAI/GPT-4o-2024-05-13 | Logistic Regression (l2) | Word2Vec | 0.727 | 0 | 0 | 0.811 |
| OpenAI/GPT-4o-2024-05-13 | Logistic Regression (l2) | FastText | 0.727 | 0.01 | 0.01 | 0.809 |
| AbacusResearch/Jallabi-34B | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.529 |
| AbacusResearch/Jallabi-34B | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.519 |
| Stark2008/GutenLaserPi | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.333 |
| Stark2008/GutenLaserPi | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.347 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.327 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.32 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.108 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.113 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.366 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.371 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.392 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.391 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | Logistic Regression (l2) | Ngrams-1 | 0.131 | 0.01 | 0 | 0.704 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.245 |
| wave-on-discord/qwent-7b | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.171 |
| Aryanne/SuperHeart | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.4 |
| Intel/neural-chat-7b-v3-2 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.263 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.329 |
| Intel/neural-chat-7b-v3-1 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.271 |
| ssmits/Qwen2.5-95B-Instruct | Logistic Regression (l2) | Ngrams-1 | 0.091 | 0 | 0 | 0.66 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.204 |
| migtissera/Tess-v2.5.2-Qwen2-72B | Logistic Regression (l2) | Ngrams-1 | 0.172 | 0 | 0 | 0.694 |
| migtissera/Llama-3-70B-Synthia-v3.5 | Logistic Regression (l2) | Ngrams-1 | 0.111 | 0 | 0 | 0.638 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.332 |
| Stark2008/VisFlamCat | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.329 |
| migtissera/Trinity-2-Codestral-22B | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.327 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.314 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.237 |
| apple/DCLM-7B | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.308 |
| Intel/neural-chat-7b-v3-3 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.266 |
| migtissera/Tess-3-Mistral-Nemo-12B | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.287 |
| migtissera/Llama-3-8B-Synthia-v3.5 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.292 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.4 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.304 |
| NousResearch/Hermes-3-Llama-3.1-70B | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.506 |
| OpenAI/GPT-4o-2024-08-06 | Logistic Regression (l2) | Ngrams-1 | 0.707 | 0.081 | 0 | 0.83 |
| BlackBeenie/llama-3-luminous-merged | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.372 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.119 |
| migtissera/Tess-3-7B-SFT | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.296 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.302 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | Logistic Regression (l2) | Ngrams-1 | 0.03 | 0 | 0 | 0.692 |
| OpenAI/GPT-4o-mini | Logistic Regression (l2) | Ngrams-1 | 0.182 | 0 | 0 | 0.747 |
| upstage/solar-pro-preview-instruct | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.547 |
| Stark2008/LayleleFlamPi | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.32 |
| NousResearch/Yarn-Llama-2-13b-128k | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.25 |
| OpenAI/GPT-4o-2024-05-13 | Logistic Regression (l2) | Ngrams-1 | 0.677 | 0.01 | 0.01 | 0.822 |
| AbacusResearch/Jallabi-34B | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.51 |
| Stark2008/GutenLaserPi | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.333 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.313 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.11 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.356 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | XGBoost | OpenAI | 0 | 0 | 0 | 0.388 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | XGBoost | OpenAI | 0 | 0 | 0 | 0.386 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | XGBoost | OpenAI | 0.222 | 0 | 0 | 0.714 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | XGBoost | OpenAI | 0 | 0 | 0 | 0.245 |
| wave-on-discord/qwent-7b | XGBoost | OpenAI | 0 | 0 | 0 | 0.152 |
| Aryanne/SuperHeart | XGBoost | OpenAI | 0 | 0 | 0 | 0.413 |
| Intel/neural-chat-7b-v3-2 | XGBoost | OpenAI | 0 | 0 | 0 | 0.274 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | XGBoost | OpenAI | 0 | 0 | 0 | 0.338 |
| Intel/neural-chat-7b-v3-1 | XGBoost | OpenAI | 0 | 0 | 0 | 0.277 |
| ssmits/Qwen2.5-95B-Instruct | XGBoost | OpenAI | 0.091 | 0.02 | 0 | 0.661 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | XGBoost | OpenAI | 0 | 0 | 0 | 0.2 |
| migtissera/Tess-v2.5.2-Qwen2-72B | XGBoost | OpenAI | 0.212 | 0.02 | 0 | 0.708 |
| migtissera/Llama-3-70B-Synthia-v3.5 | XGBoost | OpenAI | 0.152 | 0.01 | 0 | 0.642 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | XGBoost | OpenAI | 0 | 0 | 0 | 0.331 |
| Stark2008/VisFlamCat | XGBoost | OpenAI | 0 | 0 | 0 | 0.33 |
| migtissera/Trinity-2-Codestral-22B | XGBoost | OpenAI | 0 | 0 | 0 | 0.32 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | XGBoost | OpenAI | 0 | 0 | 0 | 0.295 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | XGBoost | OpenAI | 0 | 0 | 0 | 0.247 |
| apple/DCLM-7B | XGBoost | OpenAI | 0 | 0 | 0 | 0.311 |
| Intel/neural-chat-7b-v3-3 | XGBoost | OpenAI | 0 | 0 | 0 | 0.287 |
| migtissera/Tess-3-Mistral-Nemo-12B | XGBoost | OpenAI | 0 | 0 | 0 | 0.287 |
| migtissera/Llama-3-8B-Synthia-v3.5 | XGBoost | OpenAI | 0 | 0 | 0 | 0.302 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | XGBoost | OpenAI | 0 | 0 | 0 | 0.4 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | XGBoost | OpenAI | 0 | 0 | 0 | 0.32 |
| NousResearch/Hermes-3-Llama-3.1-70B | XGBoost | OpenAI | 0 | 0 | 0 | 0.483 |
| OpenAI/GPT-4o-2024-08-06 | XGBoost | OpenAI | 0.788 | 0.051 | 0.01 | 0.838 |
| BlackBeenie/llama-3-luminous-merged | XGBoost | OpenAI | 0 | 0 | 0 | 0.378 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | XGBoost | OpenAI | 0 | 0 | 0 | 0.121 |
| migtissera/Tess-3-7B-SFT | XGBoost | OpenAI | 0 | 0 | 0 | 0.311 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | XGBoost | OpenAI | 0 | 0 | 0 | 0.299 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | XGBoost | OpenAI | 0.222 | 0.061 | 0.01 | 0.709 |
| OpenAI/GPT-4o-mini | XGBoost | OpenAI | 0.303 | 0 | 0 | 0.767 |
| upstage/solar-pro-preview-instruct | XGBoost | OpenAI | 0 | 0 | 0 | 0.543 |
| Stark2008/LayleleFlamPi | XGBoost | OpenAI | 0 | 0 | 0 | 0.32 |
| NousResearch/Yarn-Llama-2-13b-128k | XGBoost | OpenAI | 0 | 0 | 0 | 0.252 |
| OpenAI/GPT-4o-2024-05-13 | XGBoost | OpenAI | 0.747 | 0.121 | 0.02 | 0.836 |
| AbacusResearch/Jallabi-34B | XGBoost | OpenAI | 0 | 0 | 0 | 0.497 |
| Stark2008/GutenLaserPi | XGBoost | OpenAI | 0 | 0 | 0 | 0.334 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | XGBoost | OpenAI | 0 | 0 | 0 | 0.312 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | XGBoost | OpenAI | 0 | 0 | 0 | 0.115 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | XGBoost | OpenAI | 0 | 0 | 0 | 0.353 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.372 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | XGBoost | FastText | 0 | 0 | 0 | 0.38 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | XGBoost | Word2Vec | 0 | 0 | 0 | 0.36 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | XGBoost | FastText | 0 | 0 | 0 | 0.367 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | XGBoost | Word2Vec | 0 | 0 | 0 | 0.692 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | XGBoost | FastText | 0.141 | 0.02 | 0 | 0.699 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.231 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | XGBoost | FastText | 0 | 0 | 0 | 0.232 |
| wave-on-discord/qwent-7b | XGBoost | Word2Vec | 0 | 0 | 0 | 0.154 |
| wave-on-discord/qwent-7b | XGBoost | FastText | 0 | 0 | 0 | 0.158 |
| Aryanne/SuperHeart | XGBoost | Word2Vec | 0 | 0 | 0 | 0.395 |
| Aryanne/SuperHeart | XGBoost | FastText | 0 | 0 | 0 | 0.393 |
| Intel/neural-chat-7b-v3-2 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.279 |
| Intel/neural-chat-7b-v3-2 | XGBoost | FastText | 0 | 0 | 0 | 0.271 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | XGBoost | Word2Vec | 0 | 0 | 0 | 0.351 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | XGBoost | FastText | 0 | 0 | 0 | 0.338 |
| Intel/neural-chat-7b-v3-1 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.258 |
| Intel/neural-chat-7b-v3-1 | XGBoost | FastText | 0 | 0 | 0 | 0.263 |
| ssmits/Qwen2.5-95B-Instruct | XGBoost | Word2Vec | 0.081 | 0 | 0 | 0.642 |
| ssmits/Qwen2.5-95B-Instruct | XGBoost | FastText | 0.02 | 0 | 0 | 0.639 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.208 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | XGBoost | FastText | 0 | 0 | 0 | 0.201 |
| migtissera/Tess-v2.5.2-Qwen2-72B | XGBoost | Word2Vec | 0.051 | 0.01 | 0 | 0.679 |
| migtissera/Tess-v2.5.2-Qwen2-72B | XGBoost | FastText | 0.03 | 0.01 | 0 | 0.682 |
| migtissera/Llama-3-70B-Synthia-v3.5 | XGBoost | Word2Vec | 0.03 | 0.01 | 0 | 0.618 |
| migtissera/Llama-3-70B-Synthia-v3.5 | XGBoost | FastText | 0.04 | 0 | 0 | 0.612 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.321 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | XGBoost | FastText | 0 | 0 | 0 | 0.335 |
| Stark2008/VisFlamCat | XGBoost | Word2Vec | 0 | 0 | 0 | 0.319 |
| Stark2008/VisFlamCat | XGBoost | FastText | 0 | 0 | 0 | 0.326 |
| migtissera/Trinity-2-Codestral-22B | XGBoost | Word2Vec | 0 | 0 | 0 | 0.339 |
| migtissera/Trinity-2-Codestral-22B | XGBoost | FastText | 0 | 0 | 0 | 0.339 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.3 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | XGBoost | FastText | 0 | 0 | 0 | 0.301 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | XGBoost | Word2Vec | 0 | 0 | 0 | 0.234 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | XGBoost | FastText | 0 | 0 | 0 | 0.243 |
| apple/DCLM-7B | XGBoost | Word2Vec | 0 | 0 | 0 | 0.315 |
| apple/DCLM-7B | XGBoost | FastText | 0 | 0 | 0 | 0.318 |
| Intel/neural-chat-7b-v3-3 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.278 |
| Intel/neural-chat-7b-v3-3 | XGBoost | FastText | 0 | 0 | 0 | 0.275 |
| migtissera/Tess-3-Mistral-Nemo-12B | XGBoost | Word2Vec | 0 | 0 | 0 | 0.282 |
| migtissera/Tess-3-Mistral-Nemo-12B | XGBoost | FastText | 0 | 0 | 0 | 0.273 |
| migtissera/Llama-3-8B-Synthia-v3.5 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.315 |
| migtissera/Llama-3-8B-Synthia-v3.5 | XGBoost | FastText | 0 | 0 | 0 | 0.3 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | XGBoost | Word2Vec | 0 | 0 | 0 | 0.406 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | XGBoost | FastText | 0 | 0 | 0 | 0.392 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.292 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | XGBoost | FastText | 0 | 0 | 0 | 0.308 |
| NousResearch/Hermes-3-Llama-3.1-70B | XGBoost | Word2Vec | 0 | 0 | 0 | 0.49 |
| NousResearch/Hermes-3-Llama-3.1-70B | XGBoost | FastText | 0 | 0 | 0 | 0.49 |
| OpenAI/GPT-4o-2024-08-06 | XGBoost | Word2Vec | 0.657 | 0.01 | 0.01 | 0.81 |
| OpenAI/GPT-4o-2024-08-06 | XGBoost | FastText | 0.677 | 0.01 | 0.01 | 0.819 |
| BlackBeenie/llama-3-luminous-merged | XGBoost | Word2Vec | 0 | 0 | 0 | 0.37 |
| BlackBeenie/llama-3-luminous-merged | XGBoost | FastText | 0 | 0 | 0 | 0.379 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.126 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | XGBoost | FastText | 0 | 0 | 0 | 0.121 |
| migtissera/Tess-3-7B-SFT | XGBoost | Word2Vec | 0 | 0 | 0 | 0.306 |
| migtissera/Tess-3-7B-SFT | XGBoost | FastText | 0 | 0 | 0 | 0.308 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.291 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | XGBoost | FastText | 0 | 0 | 0 | 0.303 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | XGBoost | Word2Vec | 0.182 | 0.071 | 0 | 0.699 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | XGBoost | FastText | 0.091 | 0 | 0 | 0.69 |
| OpenAI/GPT-4o-mini | XGBoost | Word2Vec | 0.03 | 0 | 0 | 0.722 |
| OpenAI/GPT-4o-mini | XGBoost | FastText | 0.101 | 0.01 | 0 | 0.74 |
| upstage/solar-pro-preview-instruct | XGBoost | Word2Vec | 0 | 0 | 0 | 0.543 |
| upstage/solar-pro-preview-instruct | XGBoost | FastText | 0 | 0 | 0 | 0.534 |
| Stark2008/LayleleFlamPi | XGBoost | Word2Vec | 0 | 0 | 0 | 0.318 |
| Stark2008/LayleleFlamPi | XGBoost | FastText | 0 | 0 | 0 | 0.314 |
| NousResearch/Yarn-Llama-2-13b-128k | XGBoost | Word2Vec | 0 | 0 | 0 | 0.237 |
| NousResearch/Yarn-Llama-2-13b-128k | XGBoost | FastText | 0 | 0 | 0 | 0.248 |
| OpenAI/GPT-4o-2024-05-13 | XGBoost | Word2Vec | 0.626 | 0.02 | 0 | 0.811 |
| OpenAI/GPT-4o-2024-05-13 | XGBoost | FastText | 0.646 | 0.01 | 0 | 0.81 |
| AbacusResearch/Jallabi-34B | XGBoost | Word2Vec | 0 | 0 | 0 | 0.505 |
| AbacusResearch/Jallabi-34B | XGBoost | FastText | 0 | 0 | 0 | 0.5 |
| Stark2008/GutenLaserPi | XGBoost | Word2Vec | 0 | 0 | 0 | 0.335 |
| Stark2008/GutenLaserPi | XGBoost | FastText | 0 | 0 | 0 | 0.32 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | XGBoost | Word2Vec | 0 | 0 | 0 | 0.335 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | XGBoost | FastText | 0 | 0 | 0 | 0.327 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | XGBoost | Word2Vec | 0 | 0 | 0 | 0.12 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | XGBoost | FastText | 0 | 0 | 0 | 0.13 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | XGBoost | Word2Vec | 0 | 0 | 0 | 0.358 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | XGBoost | FastText | 0 | 0 | 0 | 0.35 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.378 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.391 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | XGBoost | Ngrams-1 | 0.091 | 0.02 | 0 | 0.696 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.234 |
| wave-on-discord/qwent-7b | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.162 |
| Aryanne/SuperHeart | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.39 |
| Intel/neural-chat-7b-v3-2 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.253 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.307 |
| Intel/neural-chat-7b-v3-1 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.271 |
| ssmits/Qwen2.5-95B-Instruct | XGBoost | Ngrams-1 | 0.101 | 0.01 | 0 | 0.651 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.193 |
| migtissera/Tess-v2.5.2-Qwen2-72B | XGBoost | Ngrams-1 | 0.121 | 0.03 | 0 | 0.691 |
| migtissera/Llama-3-70B-Synthia-v3.5 | XGBoost | Ngrams-1 | 0.121 | 0 | 0 | 0.625 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.317 |
| Stark2008/VisFlamCat | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.33 |
| migtissera/Trinity-2-Codestral-22B | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.331 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.313 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.234 |
| apple/DCLM-7B | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.32 |
| Intel/neural-chat-7b-v3-3 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.252 |
| migtissera/Tess-3-Mistral-Nemo-12B | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.281 |
| migtissera/Llama-3-8B-Synthia-v3.5 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.314 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.391 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.314 |
| NousResearch/Hermes-3-Llama-3.1-70B | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.492 |
| OpenAI/GPT-4o-2024-08-06 | XGBoost | Ngrams-1 | 0.525 | 0 | 0 | 0.809 |
| BlackBeenie/llama-3-luminous-merged | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.374 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.113 |
| migtissera/Tess-3-7B-SFT | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.291 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.292 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | XGBoost | Ngrams-1 | 0.152 | 0 | 0 | 0.69 |
| OpenAI/GPT-4o-mini | XGBoost | Ngrams-1 | 0.04 | 0 | 0 | 0.72 |
| upstage/solar-pro-preview-instruct | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.563 |
| Stark2008/LayleleFlamPi | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.313 |
| NousResearch/Yarn-Llama-2-13b-128k | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.257 |
| OpenAI/GPT-4o-2024-05-13 | XGBoost | Ngrams-1 | 0.556 | 0 | 0 | 0.805 |
| AbacusResearch/Jallabi-34B | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.495 |
| Stark2008/GutenLaserPi | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.332 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.318 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.118 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.34 |
The table below shows the results of the considered LLM-assessor pairs for three minimum accuracy thresholds (0.8, 0.9, 0.95). The lower values with respect to the in-distribution case highlight the difficulty of predicting performance OOD. Additionally, the top pairs differ from the in-distribution ones, suggesting the latter may not have the highest generalisation power.
| LLM | Predictive Method | Features | 0.8 PVR | 0.9 PVR | 0.95 PVR | Area under ARC |
|---|---|---|---|---|---|---|
| Stark2008/VisFlamCat | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.558 |
| Stark2008/VisFlamCat | Logistic Regression (l1) | FastText | 0.03 | 0 | 0 | 0.547 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | Logistic Regression (l1) | Word2Vec | 0.03 | 0 | 0 | 0.684 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.624 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | Logistic Regression (l1) | Word2Vec | 0.02 | 0 | 0 | 0.753 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | Logistic Regression (l1) | FastText | 0.495 | 0 | 0 | 0.786 |
| ssmits/Qwen2.5-95B-Instruct | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.701 |
| ssmits/Qwen2.5-95B-Instruct | Logistic Regression (l1) | FastText | 0.03 | 0.01 | 0 | 0.745 |
| BlackBeenie/llama-3-luminous-merged | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.525 |
| BlackBeenie/llama-3-luminous-merged | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.485 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.332 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.294 |
| Intel/neural-chat-7b-v3-1 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.558 |
| Intel/neural-chat-7b-v3-1 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.451 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.393 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.341 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.43 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.384 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.35 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.318 |
| migtissera/Tess-v2.5.2-Qwen2-72B | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.646 |
| migtissera/Tess-v2.5.2-Qwen2-72B | Logistic Regression (l1) | FastText | 0.051 | 0 | 0 | 0.718 |
| migtissera/Tess-3-Mistral-Nemo-12B | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.46 |
| migtissera/Tess-3-Mistral-Nemo-12B | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.377 |
| Intel/neural-chat-7b-v3-2 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.557 |
| Intel/neural-chat-7b-v3-2 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.451 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.357 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.357 |
| Stark2008/GutenLaserPi | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.56 |
| Stark2008/GutenLaserPi | Logistic Regression (l1) | FastText | 0.02 | 0 | 0 | 0.541 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.562 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | Logistic Regression (l1) | FastText | 0.04 | 0 | 0 | 0.515 |
| NousResearch/Yarn-Llama-2-13b-128k | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.377 |
| NousResearch/Yarn-Llama-2-13b-128k | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.468 |
| wave-on-discord/qwent-7b | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.393 |
| wave-on-discord/qwent-7b | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.433 |
| migtissera/Trinity-2-Codestral-22B | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.586 |
| migtissera/Trinity-2-Codestral-22B | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.485 |
| migtissera/Llama-3-70B-Synthia-v3.5 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.651 |
| migtissera/Llama-3-70B-Synthia-v3.5 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.703 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.703 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | Logistic Regression (l1) | FastText | 0.111 | 0.03 | 0 | 0.744 |
| AbacusResearch/Jallabi-34B | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.636 |
| AbacusResearch/Jallabi-34B | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.601 |
| migtissera/Llama-3-8B-Synthia-v3.5 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.526 |
| migtissera/Llama-3-8B-Synthia-v3.5 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.453 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.577 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.605 |
| Aryanne/SuperHeart | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.54 |
| Aryanne/SuperHeart | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.552 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.315 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.334 |
| upstage/solar-pro-preview-instruct | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.682 |
| upstage/solar-pro-preview-instruct | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.634 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.527 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.471 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.358 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.355 |
| Intel/neural-chat-7b-v3-3 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.487 |
| Intel/neural-chat-7b-v3-3 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.534 |
| apple/DCLM-7B | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.43 |
| apple/DCLM-7B | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.379 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.389 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.386 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.527 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.488 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.513 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.476 |
| NousResearch/Hermes-3-Llama-3.1-70B | Logistic Regression (l1) | Word2Vec | 0.01 | 0 | 0 | 0.735 |
| NousResearch/Hermes-3-Llama-3.1-70B | Logistic Regression (l1) | FastText | 0.141 | 0 | 0 | 0.714 |
| Stark2008/LayleleFlamPi | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.561 |
| Stark2008/LayleleFlamPi | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.472 |
| migtissera/Tess-3-7B-SFT | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.447 |
| migtissera/Tess-3-7B-SFT | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.392 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | Logistic Regression (l1) | Word2Vec | 0 | 0 | 0 | 0.439 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | Logistic Regression (l1) | FastText | 0 | 0 | 0 | 0.477 |
| Stark2008/VisFlamCat | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.566 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.655 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.749 |
| ssmits/Qwen2.5-95B-Instruct | Logistic Regression (l1) | Ngrams-1 | 0.04 | 0 | 0 | 0.708 |
| BlackBeenie/llama-3-luminous-merged | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.526 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.282 |
| Intel/neural-chat-7b-v3-1 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.536 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.384 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.502 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.343 |
| migtissera/Tess-v2.5.2-Qwen2-72B | Logistic Regression (l1) | Ngrams-1 | 0.01 | 0 | 0 | 0.699 |
| migtissera/Tess-3-Mistral-Nemo-12B | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.511 |
| Intel/neural-chat-7b-v3-2 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.523 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.433 |
| Stark2008/GutenLaserPi | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.569 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.499 |
| NousResearch/Yarn-Llama-2-13b-128k | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.382 |
| wave-on-discord/qwent-7b | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.38 |
| migtissera/Trinity-2-Codestral-22B | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.579 |
| migtissera/Llama-3-70B-Synthia-v3.5 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.667 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.684 |
| AbacusResearch/Jallabi-34B | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.586 |
| migtissera/Llama-3-8B-Synthia-v3.5 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.495 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.569 |
| Aryanne/SuperHeart | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.551 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.296 |
| upstage/solar-pro-preview-instruct | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.71 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.51 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.31 |
| Intel/neural-chat-7b-v3-3 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.514 |
| apple/DCLM-7B | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.435 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.381 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.498 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.527 |
| NousResearch/Hermes-3-Llama-3.1-70B | Logistic Regression (l1) | Ngrams-1 | 0.04 | 0 | 0 | 0.72 |
| Stark2008/LayleleFlamPi | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.568 |
| migtissera/Tess-3-7B-SFT | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.444 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | Logistic Regression (l1) | Ngrams-1 | 0 | 0 | 0 | 0.473 |
| NousResearch/Yarn-Llama-2-13b-128k | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.398 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.524 |
| apple/DCLM-7B | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.442 |
| Intel/neural-chat-7b-v3-2 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.439 |
| Stark2008/VisFlamCat | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.546 |
| migtissera/Llama-3-70B-Synthia-v3.5 | Logistic Regression (l1) | OpenAI | 0.061 | 0 | 0 | 0.698 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.449 |
| Intel/neural-chat-7b-v3-3 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.505 |
| Aryanne/SuperHeart | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.559 |
| BlackBeenie/llama-3-luminous-merged | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.541 |
| AbacusResearch/Jallabi-34B | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.595 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.41 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.371 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.717 |
| migtissera/Tess-3-7B-SFT | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.438 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.492 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.518 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.457 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | Logistic Regression (l1) | OpenAI | 0.374 | 0 | 0 | 0.768 |
| Stark2008/LayleleFlamPi | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.534 |
| migtissera/Tess-3-Mistral-Nemo-12B | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.53 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.548 |
| migtissera/Trinity-2-Codestral-22B | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.518 |
| wave-on-discord/qwent-7b | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.405 |
| Stark2008/GutenLaserPi | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.515 |
| migtissera/Tess-v2.5.2-Qwen2-72B | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.701 |
| NousResearch/Hermes-3-Llama-3.1-70B | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.663 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.302 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.41 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.439 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.312 |
| migtissera/Llama-3-8B-Synthia-v3.5 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.51 |
| Intel/neural-chat-7b-v3-1 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.53 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.485 |
| ssmits/Qwen2.5-95B-Instruct | Logistic Regression (l1) | OpenAI | 0.01 | 0 | 0 | 0.732 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.392 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | Logistic Regression (l1) | OpenAI | 0 | 0 | 0 | 0.658 |
| upstage/solar-pro-preview-instruct | Logistic Regression (l1) | OpenAI | 0.03 | 0 | 0 | 0.726 |
| Stark2008/VisFlamCat | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.536 |
| Stark2008/VisFlamCat | Logistic Regression (l2) | FastText | 0.04 | 0 | 0 | 0.575 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | Logistic Regression (l2) | Word2Vec | 0.01 | 0 | 0 | 0.693 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | Logistic Regression (l2) | FastText | 0.04 | 0 | 0 | 0.641 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | Logistic Regression (l2) | Word2Vec | 0.03 | 0 | 0 | 0.741 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | Logistic Regression (l2) | FastText | 0.485 | 0.04 | 0 | 0.784 |
| ssmits/Qwen2.5-95B-Instruct | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.713 |
| ssmits/Qwen2.5-95B-Instruct | Logistic Regression (l2) | FastText | 0.01 | 0 | 0 | 0.748 |
| BlackBeenie/llama-3-luminous-merged | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.519 |
| BlackBeenie/llama-3-luminous-merged | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.519 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.322 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.27 |
| Intel/neural-chat-7b-v3-1 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.548 |
| Intel/neural-chat-7b-v3-1 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.551 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.367 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.369 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.398 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.389 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.332 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.325 |
| migtissera/Tess-v2.5.2-Qwen2-72B | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.636 |
| migtissera/Tess-v2.5.2-Qwen2-72B | Logistic Regression (l2) | FastText | 0.051 | 0 | 0 | 0.716 |
| migtissera/Tess-3-Mistral-Nemo-12B | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.496 |
| migtissera/Tess-3-Mistral-Nemo-12B | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.417 |
| Intel/neural-chat-7b-v3-2 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.512 |
| Intel/neural-chat-7b-v3-2 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.502 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.361 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.373 |
| Stark2008/GutenLaserPi | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.552 |
| Stark2008/GutenLaserPi | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.572 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.566 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | Logistic Regression (l2) | FastText | 0.04 | 0 | 0 | 0.512 |
| NousResearch/Yarn-Llama-2-13b-128k | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.356 |
| NousResearch/Yarn-Llama-2-13b-128k | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.429 |
| wave-on-discord/qwent-7b | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.394 |
| wave-on-discord/qwent-7b | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.4 |
| migtissera/Trinity-2-Codestral-22B | Logistic Regression (l2) | Word2Vec | 0.03 | 0.01 | 0 | 0.603 |
| migtissera/Trinity-2-Codestral-22B | Logistic Regression (l2) | FastText | 0.02 | 0 | 0 | 0.568 |
| migtissera/Llama-3-70B-Synthia-v3.5 | Logistic Regression (l2) | Word2Vec | 0.04 | 0 | 0 | 0.655 |
| migtissera/Llama-3-70B-Synthia-v3.5 | Logistic Regression (l2) | FastText | 0.01 | 0 | 0 | 0.702 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.698 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | Logistic Regression (l2) | FastText | 0.091 | 0.03 | 0 | 0.742 |
| AbacusResearch/Jallabi-34B | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.647 |
| AbacusResearch/Jallabi-34B | Logistic Regression (l2) | FastText | 0.061 | 0 | 0 | 0.63 |
| migtissera/Llama-3-8B-Synthia-v3.5 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.521 |
| migtissera/Llama-3-8B-Synthia-v3.5 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.471 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.599 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | Logistic Regression (l2) | FastText | 0.061 | 0 | 0 | 0.62 |
| Aryanne/SuperHeart | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.528 |
| Aryanne/SuperHeart | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.528 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.284 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.328 |
| upstage/solar-pro-preview-instruct | Logistic Regression (l2) | Word2Vec | 0.01 | 0 | 0 | 0.706 |
| upstage/solar-pro-preview-instruct | Logistic Regression (l2) | FastText | 0.061 | 0 | 0 | 0.693 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.502 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.481 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.335 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.309 |
| Intel/neural-chat-7b-v3-3 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.506 |
| Intel/neural-chat-7b-v3-3 | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.547 |
| apple/DCLM-7B | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.429 |
| apple/DCLM-7B | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.392 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.4 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.403 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.521 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | Logistic Regression (l2) | FastText | 0.03 | 0 | 0 | 0.536 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.516 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.504 |
| NousResearch/Hermes-3-Llama-3.1-70B | Logistic Regression (l2) | Word2Vec | 0.02 | 0 | 0 | 0.731 |
| NousResearch/Hermes-3-Llama-3.1-70B | Logistic Regression (l2) | FastText | 0.051 | 0 | 0 | 0.722 |
| Stark2008/LayleleFlamPi | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.511 |
| Stark2008/LayleleFlamPi | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.573 |
| migtissera/Tess-3-7B-SFT | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.436 |
| migtissera/Tess-3-7B-SFT | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.445 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | Logistic Regression (l2) | Word2Vec | 0 | 0 | 0 | 0.418 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | Logistic Regression (l2) | FastText | 0 | 0 | 0 | 0.469 |
| Stark2008/VisFlamCat | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.498 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.619 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.752 |
| ssmits/Qwen2.5-95B-Instruct | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.718 |
| BlackBeenie/llama-3-luminous-merged | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.467 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.309 |
| Intel/neural-chat-7b-v3-1 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.47 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.381 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.45 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.324 |
| migtissera/Tess-v2.5.2-Qwen2-72B | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.687 |
| migtissera/Tess-3-Mistral-Nemo-12B | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.457 |
| Intel/neural-chat-7b-v3-2 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.461 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.418 |
| Stark2008/GutenLaserPi | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.5 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.485 |
| NousResearch/Yarn-Llama-2-13b-128k | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.383 |
| wave-on-discord/qwent-7b | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.42 |
| migtissera/Trinity-2-Codestral-22B | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.515 |
| migtissera/Llama-3-70B-Synthia-v3.5 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.669 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.724 |
| AbacusResearch/Jallabi-34B | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.587 |
| migtissera/Llama-3-8B-Synthia-v3.5 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.474 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.522 |
| Aryanne/SuperHeart | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.471 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.31 |
| upstage/solar-pro-preview-instruct | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.682 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.474 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.314 |
| Intel/neural-chat-7b-v3-3 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.482 |
| apple/DCLM-7B | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.436 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.382 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.468 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.427 |
| NousResearch/Hermes-3-Llama-3.1-70B | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.632 |
| Stark2008/LayleleFlamPi | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.483 |
| migtissera/Tess-3-7B-SFT | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.434 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | Logistic Regression (l2) | Ngrams-1 | 0 | 0 | 0 | 0.427 |
| NousResearch/Yarn-Llama-2-13b-128k | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.348 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.513 |
| apple/DCLM-7B | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.436 |
| Intel/neural-chat-7b-v3-2 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.452 |
| Stark2008/VisFlamCat | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.52 |
| migtissera/Llama-3-70B-Synthia-v3.5 | Logistic Regression (l2) | OpenAI | 0.152 | 0 | 0 | 0.711 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.432 |
| Intel/neural-chat-7b-v3-3 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.446 |
| Aryanne/SuperHeart | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.558 |
| BlackBeenie/llama-3-luminous-merged | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.552 |
| AbacusResearch/Jallabi-34B | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.594 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.384 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.332 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | Logistic Regression (l2) | OpenAI | 0.162 | 0 | 0 | 0.731 |
| migtissera/Tess-3-7B-SFT | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.423 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.533 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.51 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.492 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | Logistic Regression (l2) | OpenAI | 0.303 | 0 | 0 | 0.773 |
| Stark2008/LayleleFlamPi | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.512 |
| migtissera/Tess-3-Mistral-Nemo-12B | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.462 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.559 |
| migtissera/Trinity-2-Codestral-22B | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.544 |
| wave-on-discord/qwent-7b | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.418 |
| Stark2008/GutenLaserPi | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.53 |
| migtissera/Tess-v2.5.2-Qwen2-72B | Logistic Regression (l2) | OpenAI | 0.242 | 0 | 0 | 0.739 |
| NousResearch/Hermes-3-Llama-3.1-70B | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.659 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.304 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.377 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.428 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.311 |
| migtissera/Llama-3-8B-Synthia-v3.5 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.498 |
| Intel/neural-chat-7b-v3-1 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.523 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.542 |
| ssmits/Qwen2.5-95B-Instruct | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.749 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.394 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | Logistic Regression (l2) | OpenAI | 0 | 0 | 0 | 0.644 |
| upstage/solar-pro-preview-instruct | Logistic Regression (l2) | OpenAI | 0.03 | 0 | 0 | 0.724 |
| Stark2008/VisFlamCat | XGBoost | Word2Vec | 0 | 0 | 0 | 0.529 |
| Stark2008/VisFlamCat | XGBoost | FastText | 0 | 0 | 0 | 0.555 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | XGBoost | Word2Vec | 0 | 0 | 0 | 0.644 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | XGBoost | FastText | 0 | 0 | 0 | 0.671 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | XGBoost | Word2Vec | 0.03 | 0 | 0 | 0.737 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | XGBoost | FastText | 0.303 | 0 | 0 | 0.769 |
| ssmits/Qwen2.5-95B-Instruct | XGBoost | Word2Vec | 0 | 0 | 0 | 0.684 |
| ssmits/Qwen2.5-95B-Instruct | XGBoost | FastText | 0.091 | 0 | 0 | 0.743 |
| BlackBeenie/llama-3-luminous-merged | XGBoost | Word2Vec | 0 | 0 | 0 | 0.489 |
| BlackBeenie/llama-3-luminous-merged | XGBoost | FastText | 0 | 0 | 0 | 0.504 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.301 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | XGBoost | FastText | 0 | 0 | 0 | 0.313 |
| Intel/neural-chat-7b-v3-1 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.52 |
| Intel/neural-chat-7b-v3-1 | XGBoost | FastText | 0 | 0 | 0 | 0.511 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.394 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | XGBoost | FastText | 0 | 0 | 0 | 0.4 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.444 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | XGBoost | FastText | 0 | 0 | 0 | 0.398 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.338 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | XGBoost | FastText | 0 | 0 | 0 | 0.326 |
| migtissera/Tess-v2.5.2-Qwen2-72B | XGBoost | Word2Vec | 0.01 | 0 | 0 | 0.654 |
| migtissera/Tess-v2.5.2-Qwen2-72B | XGBoost | FastText | 0 | 0 | 0 | 0.703 |
| migtissera/Tess-3-Mistral-Nemo-12B | XGBoost | Word2Vec | 0 | 0 | 0 | 0.502 |
| migtissera/Tess-3-Mistral-Nemo-12B | XGBoost | FastText | 0.01 | 0 | 0 | 0.531 |
| Intel/neural-chat-7b-v3-2 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.543 |
| Intel/neural-chat-7b-v3-2 | XGBoost | FastText | 0 | 0 | 0 | 0.561 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.411 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | XGBoost | FastText | 0 | 0 | 0 | 0.395 |
| Stark2008/GutenLaserPi | XGBoost | Word2Vec | 0 | 0 | 0 | 0.529 |
| Stark2008/GutenLaserPi | XGBoost | FastText | 0 | 0 | 0 | 0.557 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | XGBoost | Word2Vec | 0 | 0 | 0 | 0.568 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | XGBoost | FastText | 0 | 0 | 0 | 0.575 |
| NousResearch/Yarn-Llama-2-13b-128k | XGBoost | Word2Vec | 0 | 0 | 0 | 0.428 |
| NousResearch/Yarn-Llama-2-13b-128k | XGBoost | FastText | 0 | 0 | 0 | 0.429 |
| wave-on-discord/qwent-7b | XGBoost | Word2Vec | 0 | 0 | 0 | 0.448 |
| wave-on-discord/qwent-7b | XGBoost | FastText | 0 | 0 | 0 | 0.44 |
| migtissera/Trinity-2-Codestral-22B | XGBoost | Word2Vec | 0 | 0 | 0 | 0.536 |
| migtissera/Trinity-2-Codestral-22B | XGBoost | FastText | 0 | 0 | 0 | 0.538 |
| migtissera/Llama-3-70B-Synthia-v3.5 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.65 |
| migtissera/Llama-3-70B-Synthia-v3.5 | XGBoost | FastText | 0 | 0 | 0 | 0.677 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | XGBoost | Word2Vec | 0 | 0 | 0 | 0.7 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | XGBoost | FastText | 0 | 0 | 0 | 0.679 |
| AbacusResearch/Jallabi-34B | XGBoost | Word2Vec | 0 | 0 | 0 | 0.628 |
| AbacusResearch/Jallabi-34B | XGBoost | FastText | 0 | 0 | 0 | 0.619 |
| migtissera/Llama-3-8B-Synthia-v3.5 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.502 |
| migtissera/Llama-3-8B-Synthia-v3.5 | XGBoost | FastText | 0 | 0 | 0 | 0.517 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.585 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | XGBoost | FastText | 0 | 0 | 0 | 0.584 |
| Aryanne/SuperHeart | XGBoost | Word2Vec | 0 | 0 | 0 | 0.52 |
| Aryanne/SuperHeart | XGBoost | FastText | 0 | 0 | 0 | 0.484 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | XGBoost | Word2Vec | 0 | 0 | 0 | 0.296 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | XGBoost | FastText | 0 | 0 | 0 | 0.326 |
| upstage/solar-pro-preview-instruct | XGBoost | Word2Vec | 0 | 0 | 0 | 0.677 |
| upstage/solar-pro-preview-instruct | XGBoost | FastText | 0 | 0 | 0 | 0.713 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | XGBoost | Word2Vec | 0 | 0 | 0 | 0.54 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | XGBoost | FastText | 0 | 0 | 0 | 0.486 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.343 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | XGBoost | FastText | 0 | 0 | 0 | 0.389 |
| Intel/neural-chat-7b-v3-3 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.467 |
| Intel/neural-chat-7b-v3-3 | XGBoost | FastText | 0 | 0 | 0 | 0.547 |
| apple/DCLM-7B | XGBoost | Word2Vec | 0 | 0 | 0 | 0.431 |
| apple/DCLM-7B | XGBoost | FastText | 0 | 0 | 0 | 0.448 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | XGBoost | Word2Vec | 0 | 0 | 0 | 0.41 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | XGBoost | FastText | 0 | 0 | 0 | 0.38 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | XGBoost | Word2Vec | 0 | 0 | 0 | 0.55 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | XGBoost | FastText | 0 | 0 | 0 | 0.53 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | XGBoost | Word2Vec | 0 | 0 | 0 | 0.55 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | XGBoost | FastText | 0 | 0 | 0 | 0.506 |
| NousResearch/Hermes-3-Llama-3.1-70B | XGBoost | Word2Vec | 0.02 | 0 | 0 | 0.699 |
| NousResearch/Hermes-3-Llama-3.1-70B | XGBoost | FastText | 0 | 0 | 0 | 0.637 |
| Stark2008/LayleleFlamPi | XGBoost | Word2Vec | 0 | 0 | 0 | 0.527 |
| Stark2008/LayleleFlamPi | XGBoost | FastText | 0 | 0 | 0 | 0.545 |
| migtissera/Tess-3-7B-SFT | XGBoost | Word2Vec | 0 | 0 | 0 | 0.464 |
| migtissera/Tess-3-7B-SFT | XGBoost | FastText | 0 | 0 | 0 | 0.493 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | XGBoost | Word2Vec | 0 | 0 | 0 | 0.462 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | XGBoost | FastText | 0 | 0 | 0 | 0.448 |
| Stark2008/VisFlamCat | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.558 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.595 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | XGBoost | Ngrams-1 | 0.03 | 0 | 0 | 0.756 |
| ssmits/Qwen2.5-95B-Instruct | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.694 |
| BlackBeenie/llama-3-luminous-merged | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.484 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.316 |
| Intel/neural-chat-7b-v3-1 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.535 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.426 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.441 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.361 |
| migtissera/Tess-v2.5.2-Qwen2-72B | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.673 |
| migtissera/Tess-3-Mistral-Nemo-12B | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.5 |
| Intel/neural-chat-7b-v3-2 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.465 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.412 |
| Stark2008/GutenLaserPi | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.552 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.458 |
| NousResearch/Yarn-Llama-2-13b-128k | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.336 |
| wave-on-discord/qwent-7b | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.399 |
| migtissera/Trinity-2-Codestral-22B | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.587 |
| migtissera/Llama-3-70B-Synthia-v3.5 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.657 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.679 |
| AbacusResearch/Jallabi-34B | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.616 |
| migtissera/Llama-3-8B-Synthia-v3.5 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.473 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.574 |
| Aryanne/SuperHeart | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.524 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.291 |
| upstage/solar-pro-preview-instruct | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.678 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.525 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.324 |
| Intel/neural-chat-7b-v3-3 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.464 |
| apple/DCLM-7B | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.373 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.364 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.53 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.47 |
| NousResearch/Hermes-3-Llama-3.1-70B | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.639 |
| Stark2008/LayleleFlamPi | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.54 |
| migtissera/Tess-3-7B-SFT | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.469 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | XGBoost | Ngrams-1 | 0 | 0 | 0 | 0.413 |
| NousResearch/Yarn-Llama-2-13b-128k | XGBoost | OpenAI | 0 | 0 | 0 | 0.381 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored | XGBoost | OpenAI | 0 | 0 | 0 | 0.494 |
| apple/DCLM-7B | XGBoost | OpenAI | 0 | 0 | 0 | 0.411 |
| Intel/neural-chat-7b-v3-2 | XGBoost | OpenAI | 0 | 0 | 0 | 0.487 |
| Stark2008/VisFlamCat | XGBoost | OpenAI | 0 | 0 | 0 | 0.495 |
| migtissera/Llama-3-70B-Synthia-v3.5 | XGBoost | OpenAI | 0 | 0 | 0 | 0.676 |
| awnr/Mistral-7B-v0.1-signtensors-7-over-16 | XGBoost | OpenAI | 0 | 0 | 0 | 0.42 |
| Intel/neural-chat-7b-v3-3 | XGBoost | OpenAI | 0 | 0 | 0 | 0.457 |
| Aryanne/SuperHeart | XGBoost | OpenAI | 0 | 0 | 0 | 0.548 |
| BlackBeenie/llama-3-luminous-merged | XGBoost | OpenAI | 0 | 0 | 0 | 0.521 |
| AbacusResearch/Jallabi-34B | XGBoost | OpenAI | 0 | 0 | 0 | 0.586 |
| awnr/Mistral-7B-v0.1-signtensors-5-over-16 | XGBoost | OpenAI | 0 | 0 | 0 | 0.404 |
| awnr/Mistral-7B-v0.1-signtensors-1-over-4 | XGBoost | OpenAI | 0 | 0 | 0 | 0.353 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | XGBoost | OpenAI | 0.01 | 0 | 0 | 0.686 |
| migtissera/Tess-3-7B-SFT | XGBoost | OpenAI | 0 | 0 | 0 | 0.424 |
| migtissera/Trinity-2-Codestral-22B-v0.2 | XGBoost | OpenAI | 0 | 0 | 0 | 0.561 |
| xxx777xxxASD/L3.1-ClaudeMaid-4x8B | XGBoost | OpenAI | 0 | 0 | 0 | 0.521 |
| argilla-warehouse/Llama-3.1-8B-MagPie-Ultra | XGBoost | OpenAI | 0 | 0 | 0 | 0.472 |
| MaziyarPanahi/calme-2.1-qwen2.5-72b | XGBoost | OpenAI | 0 | 0 | 0 | 0.733 |
| Stark2008/LayleleFlamPi | XGBoost | OpenAI | 0 | 0 | 0 | 0.496 |
| migtissera/Tess-3-Mistral-Nemo-12B | XGBoost | OpenAI | 0 | 0 | 0 | 0.493 |
| BlackBeenie/llama-3.1-8B-Galore-openassistant-guanaco | XGBoost | OpenAI | 0 | 0 | 0 | 0.544 |
| migtissera/Trinity-2-Codestral-22B | XGBoost | OpenAI | 0 | 0 | 0 | 0.573 |
| wave-on-discord/qwent-7b | XGBoost | OpenAI | 0 | 0 | 0 | 0.416 |
| Stark2008/GutenLaserPi | XGBoost | OpenAI | 0 | 0 | 0 | 0.543 |
| migtissera/Tess-v2.5.2-Qwen2-72B | XGBoost | OpenAI | 0.01 | 0 | 0 | 0.706 |
| NousResearch/Hermes-3-Llama-3.1-70B | XGBoost | OpenAI | 0 | 0 | 0 | 0.659 |
| LenguajeNaturalAI/leniachat-gemma-2b-v0 | XGBoost | OpenAI | 0 | 0 | 0 | 0.319 |
| LenguajeNaturalAI/leniachat-qwen2-1.5B-v0 | XGBoost | OpenAI | 0 | 0 | 0 | 0.392 |
| awnr/Mistral-7B-v0.1-signtensors-3-over-8 | XGBoost | OpenAI | 0 | 0 | 0 | 0.45 |
| jaredjoss/pythia-410m-roberta-lr 8e7-kl 01-steps 12000-rlhf-model | XGBoost | OpenAI | 0 | 0 | 0 | 0.288 |
| migtissera/Llama-3-8B-Synthia-v3.5 | XGBoost | OpenAI | 0 | 0 | 0 | 0.476 |
| Intel/neural-chat-7b-v3-1 | XGBoost | OpenAI | 0 | 0 | 0 | 0.491 |
| Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2 | XGBoost | OpenAI | 0 | 0 | 0 | 0.522 |
| ssmits/Qwen2.5-95B-Instruct | XGBoost | OpenAI | 0 | 0 | 0 | 0.703 |
| ymcki/gemma-2-2b-ORPO-jpn-it-abliterated-18-merge | XGBoost | OpenAI | 0 | 0 | 0 | 0.386 |
| migtissera/Tess-v2.5-Phi-3-medium-128k-14B | XGBoost | OpenAI | 0 | 0 | 0 | 0.603 |
| upstage/solar-pro-preview-instruct | XGBoost | OpenAI | 0.091 | 0 | 0 | 0.733 |

OpenAI/GPT-4o-2024-08-06) on MMLU-Pro.
@inproceedings{pacchiardi-etal-2025-predictaboard,
title = "{P}redicta{B}oard: Benchmarking {LLM} Score Predictability",
author = "Pacchiardi, Lorenzo and
Voudouris, Konstantinos and
Slater, Ben and
Mart{\'i}nez-Plumed, Fernando and
Hernandez-Orallo, Jose and
Zhou, Lexin and
Schellaert, Wout",
editor = "Che, Wanxiang and
Nabende, Joyce and
Shutova, Ekaterina and
Pilehvar, Mohammad Taher",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2025",
month = jul,
year = "2025",
address = "Vienna, Austria",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.findings-acl.790/",
doi = "10.18653/v1/2025.findings-acl.790",
pages = "15245--15266",
ISBN = "979-8-89176-256-5",
}